Introduction
The join operation is a fundamental building block of parallel data processing. Unfortunately, it is very resource-intensive to compute an equi-join across massive datasets. The approximate computing paradigm allows users to trade accuracy and latency for expensive data processing operations. The equi-join operator is thus a natural candidate for optimization using approximation techniques.
Although sampling-based approaches are widely used for approximation, sampling over joins is a compelling but challenging task regarding the output quality. Naive approaches, which perform joins over dataset samples, would not preserve statistical properties of the join output.
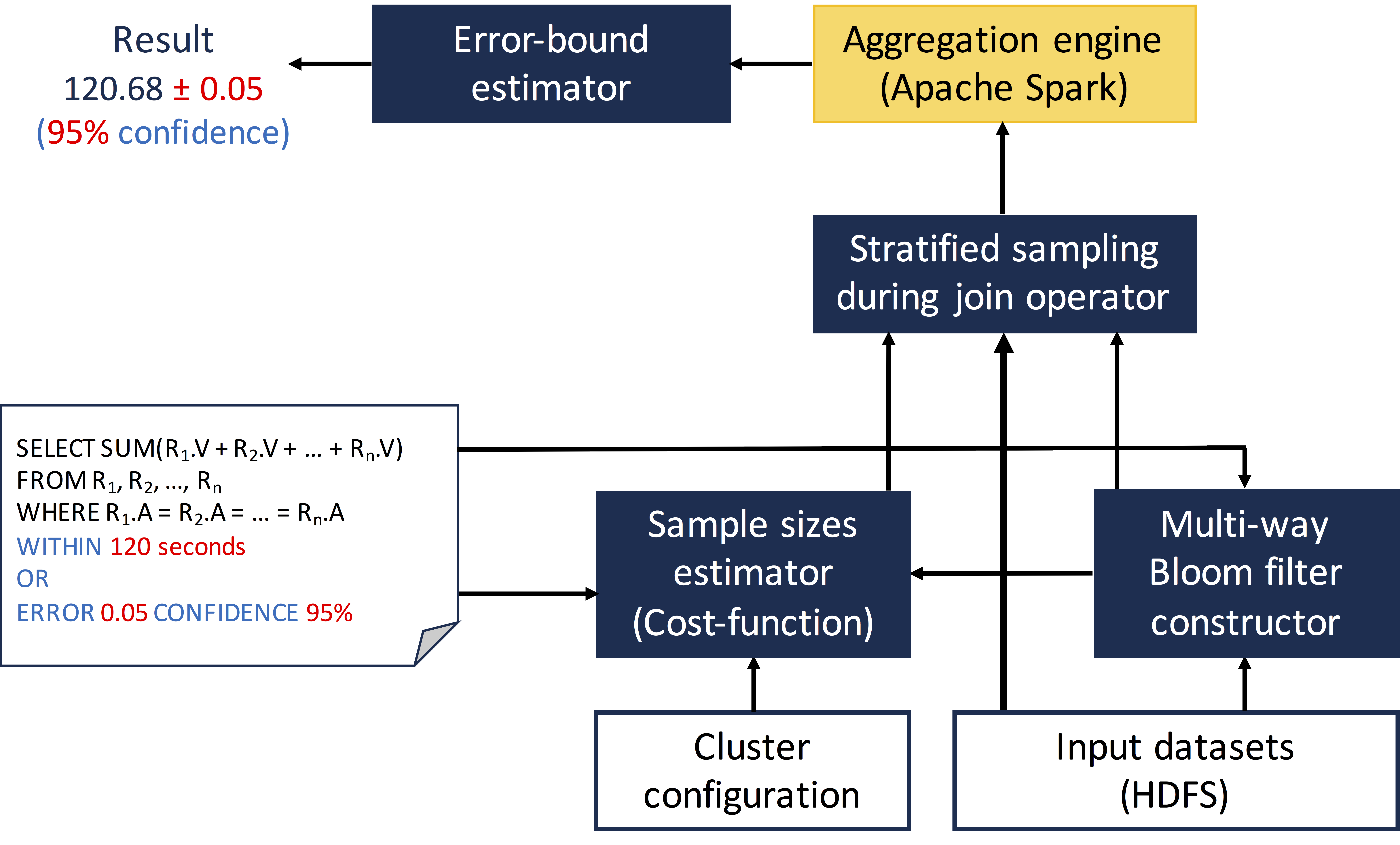
To realize this potential, we interweave Bloom filter sketching and stratified sampling with the join computation in a new operator, ApproxJoin, that preserves the statistical properties of the join output. ApproxJoin leverages a Bloom filter to avoid shuffling non-joinable data items around the network and then applies stratified sampling to obtain a representative sample of the join output. Our analysis shows thatApproxJoin scales well and significantly reduces data movement, without sacrificing tight error bounds on the accuracy of the final results.
Source Code
Source code will be available soon.
- Cluster deployment script
News
- This work has been accepted to ACM SoCC’18, see you in Carlsbad, California!